AIоƬ����a(ch��n)�I(y��)���ģ�Ҳ�Ǽ��g(sh��)Ҫ�����ֵ��ߵĭh(hu��n)��(ji��)����AI�a(ch��n)�I(y��)��еĮa(ch��n)�I(y��)�r(ji��)ֵ�͑�(zh��n)�Ե�λ�h(yu��n)�h(yu��n)���ڑ�(y��ng)�Ìӄ�(chu��ng)�¡��vӍ�l(f��)���ġ������ɇ�(gu��)�˹����ܮa(ch��n)�I(y��)�l(f��)չȫ����x����(b��o)���@ʾ�����A(ch��)�ӵ�̎����/оƬ��I(y��)��(sh��)���������Ї�(gu��)��14�ң�����(gu��)33�ҡ����Č���(du��)�@һ�I(l��ng)��a(ch��n)�I(y��)���B(t��i)��һ��(g��)��(ji��n)��������
AIоƬ���
Training�h(hu��n)��(ji��)ͨ����Ҫͨ�^�����Ĕ�(sh��)��(j��)ݔ�룬���ȡ����(qi��ng)�W(xu��)��(x��)�ȷDZO(ji��n)���W(xu��)��(x��)������Ӗ(x��n)����һ��(g��)��(f��)�s�������(j��ng)�W(w��ng)�j(lu��)ģ�͡�Ӗ(x��n)���^�������漰������Ӗ(x��n)����(sh��)��(j��)�͏�(f��)�s�������(j��ng)�W(w��ng)�j(lu��)�Y(ji��)��(g��u)���\(y��n)��������Ҫ�����Ӌ(j��)��Ҏ(gu��)ģ����(du��)��̎������Ӌ(j��)�����������ȡ��ɔU(ku��)չ�Ե�����Ҫ��ܸߡ�Ŀǰ��Ӗ(x��n)���h(hu��n)��(ji��)��Ҫʹ��NVIDIA��GPU��Ⱥ����ɣ�Google�����аl(f��)��ASICоƬTPU2.0Ҳ֧��Ӗ(x��n)���h(hu��n)��(ji��)����ȾW(w��ng)�j(lu��)���١�
Inference�h(hu��n)��(ji��)ָ����Ӗ(x��n)���õ�ģ�ͣ�ʹ���µĔ�(sh��)��(j��)ȥ�������������N�Y(ji��)Փ����ҕ�l�O(ji��n)���O(sh��)��ͨ�^���_(t��i)�������(j��ng)�W(w��ng)�j(lu��)ģ�ͣ��Д�һ��ץ�ĵ�����Ę�Ƿ���ں����Ρ��mȻInference��Ӌ(j��)�������Training�ٺܶ࣬����Ȼ�漰�����ľ���\(y��n)�㡣�������h(hu��n)��(ji��)��GPU��FPGA��ASIC���кܶ���(y��ng)�Ãr(ji��)ֵ��
����ȌW(xu��)��(x��)��Training�A�Σ����ڌ�(du��)��(sh��)��(j��)�����\(y��n)���������һ̎�����������ܪ�(d��)�����һ��(g��)ģ�͵�Ӗ(x��n)���^�̣���ˣ�Training�h(hu��n)��(ji��)Ŀǰֻ�����ƶˌ�(sh��)�F(xi��n)�����O(sh��)�����TrainingĿǰ߀���Ǻ����_������
��Inference�A�Σ�����ĿǰӖ(x��n)�������������(j��ng)�W(w��ng)�j(lu��)ģ�ʹ���Էdz���(f��)�s���������^����Ȼ��Ӌ(j��)���ܼ��ͺʹ惦(ch��)�ܼ��͵ģ��������YԴ���ĽK���Ñ��O(sh��)�����y�Ⱥܴ���ˣ��ƶ�����Ŀǰ���˹����ܑ�(y��ng)��������������@��GPU��FPGA��ASIC(Google TPU1.0/2.0)�ȶ��ё�(y��ng)�����ƶ�Inference�h(hu��n)�������O(sh��)���Inference�I(l��ng)���������ܽK�˔�(sh��)�������������^����ADAS��VR���O(sh��)�䌦(du��)��(sh��)�r(sh��)��Ҫ��ܸߣ������^�̲��ܽ����ƶ���ɣ�Ҫ��K���O(sh��)�䱾����Ҫ�߂���������Ӌ(j��)�����������һЩ���ġ������t���ͳɱ��Č���оƬҲ��(hu��)�кܴ���Ј�(ch��ng)����
���������ɷN����҂��ó�AIоƬ����������D��ʾ��
���˰��չ��܈�(ch��ng)�������⣬AIоƬ�ļ��g(sh��)�ܘ�(g��u)�l(f��)չ����������Ҳ���Է֞��Ă�(g��)��ͣ�
-
ͨ���оƬ��������GPU��FPGA��
-
����FPGA�İ붨�ƻ�оƬ�����������b�Ƽ�DPU���ٶ�XPU�ȣ�
-
ȫ���ƻ�ASICоƬ��������TPU������o(j��) Cambricon-1A�ȣ�
-
��XӋ(j��)��оƬ��������IBM TrueNorth��westwell����ͨZeroth�ȡ�
AIоƬ�a(ch��n)�I(y��)���B(t��i)
������������ށ�����ĿǰAIоƬ���Ј�(ch��ng)������Ҫ�����
-
�����ڸ����˹�������I(y��)����(sh��)�(y��n)���аl(f��)�A�ε�Training����(��Ҫ���ƶˣ��O(sh��)���Training�����в����_)��
-
Inference On Cloud��F(xi��n)ace++�����T������Siri�������˹����ܑ�(y��ng)�þ�ͨ�^�ƶ��ṩ����(w��)��
-
Inference On Device�����������֙C(j��)�����ܔz���^���C(j��)����/�o(w��)�˙C(j��)���Ԅ�(d��ng)�{VR���O(sh��)����O(sh��)��������Ј�(ch��ng)����Ҫ�߶ȶ��ƻ������ĵ�AIоƬ�a(ch��n)Ʒ�����A������970���d�ˡ���(j��ng)�W(w��ng)�j(lu��)̎���Ԫ(NPU����(sh��)�H�麮��o(j��)��IP)�����O��A11���d�ˡ���(j��ng)�W(w��ng)�j(lu��)����(Neural Engine)����
��һ��TrainingӖ(x��n)��
2007����ǰ���˹������о������ڮ�(d��ng)�r(sh��)�㷨����(sh��)��(j��)�����أ���(du��)��оƬ���]���e��(qi��ng)�ҵ�����ͨ�õ�CPUоƬ�����ṩ����Ӌ(j��)��������Andrew Ng��Jeff Dean�����Google Brain�(xi��ng)Ŀ��ʹ�ð���16000��(g��)CPU�˵IJ���Ӌ(j��)��ƽ�_(t��i)��Ӗ(x��n)�����^10�|��(g��)��(j��ng)Ԫ�������(j��ng)�W(w��ng)�j(lu��)����CPU�Ĵ��нY(ji��)��(g��u)�����m������ȌW(xu��)��(x��)����ĺ�����(sh��)��(j��)�\(y��n)��������CPU����ȌW(xu��)��(x��)Ӗ(x��n)��Ч�ʺܵͣ�������ʹ����ȌW(xu��)��(x��)�㷨�M(j��n)���Z(y��)���R(sh��)�e��ģ���У�����429��(g��)��(j��ng)Ԫ��ݔ��ӣ�����(g��)�W(w��ng)�j(lu��)����156M��(g��)����(sh��)��Ӗ(x��n)���r(sh��)�g���^75�졣
�cCPU������߉�\(y��n)���Ԫ��ȣ�GPU����(g��)����һ��(g��)�����Ӌ(j��)���ꇣ�GPU���Д�(sh��)��ǧӋ(j��)��Ӌ(j��)����ġ��Ɍ�(sh��)�F(xi��n)10-100����(y��ng)����������������߀֧��(du��)��ȌW(xu��)��(x��)���P(gu��n)��Ҫ�IJ���Ӌ(j��)�����������ԱȂ��y(t��ng)̎�������ӿ��٣����ӿ���Ӗ(x��n)���^�̡�
���ψD��(du��)�ȁ������ڃ�(n��i)���Y(ji��)��(g��u)�ϣ�CPU��70%���w�ܶ����Á혋(g��u)��Cache(���پ��_�惦(ch��)��)��һ���ֿ��Ɔ�Ԫ��ؓ(f��)؟(z��)߉�\(y��n)��IJ���(ALUģ�K)�����ָ࣬���(zh��)����һ�l��һ�l�Ĵ����^�̡�GPU �ɲ���Ӌ(j��)���Ԫ�Ϳ��Ɔ�Ԫ�Լ��惦(ch��)��Ԫ��(g��u)�ɣ����д����ĺ�(���_(d��)��ǧ��(g��))�ʹ����ĸ��ك�(n��i)�棬���L(zh��ng)����ƈD��̎���IJ���Ӌ(j��)�㣬�Ծ�ꇵķֲ�ʽ��ʽ�팍(sh��)�F(xi��n)Ӌ(j��)�㡣ͬCPU��ͬ���ǣ�GPU��Ӌ(j��)���Ԫ���@���࣬�e�m�ϴ�Ҏ(gu��)ģ����Ӌ(j��)�㡣

���˹����ܵ�ͨ��Ӌ(j��)��GPU�Ј�(ch��ng)��NVIDIA�F(xi��n)��һ�Ҫ�(d��)��2010��NVIDIA���_ʼ�����˹����ܮa(ch��n)Ʒ��2014��l(f��)������һ��PASCAL GPUоƬ�ܘ�(g��u)���@��NVIDIA�ĵ����GPU�ܘ�(g��u)��Ҳ���ׂ�(g��)����ȌW(xu��)��(x��)���O(sh��)Ӌ(j��)��GPU����֧��������������ȌW(xu��)��(x��)Ӌ(j��)���ܡ�2016���ϰ��꣬NVIDIA��ᘌ�(du��)��(j��ng)�W(w��ng)�j(lu��)Ӗ(x��n)���^���Ƴ��˻���PASCAL�ܘ�(g��u)��TESLA P100оƬ�Լ�����(y��ng)�ij���(j��)Ӌ(j��)��C(j��)DGX-1��DGX-1����TESLA P100 GPU������������NVLINK��(li��n)���g(sh��)��ܛ���ї�������Ҫ��ȌW(xu��)��(x��)��ܡ���ȌW(xu��)��(x��)SDK��DIGITS GPUӖ(x��n)��ϵ�y(t��ng)���(q��)��(d��ng)�����CUDA���܉�����O(sh��)Ӌ(j��)�����(j��ng)�W(w��ng)�j(lu��)(DNN)�����и��_(d��)170TFLOPS�İ뾫�ȸ��c(di��n)�\(y��n)���������ஔ(d��ng)��250�_(t��i)���y(t��ng)����(w��)�������Ԍ���ȌW(xu��)��(x��)��Ӗ(x��n)���ٶȼӿ�75������CPU��������56����
Training�Ј�(ch��ng)Ŀǰ���cNVIDIA��(j��ng)��(zh��ng)�ľ���Google������5�·�Google�l(f��)����TPU 2.0��TPU(TensorProcessing Unit)��Google�аl(f��)��һ��ᘌ�(du��)��ȌW(xu��)��(x��)���ٵ�ASICоƬ����һ��TPU�H��������������Ŀǰ�l(f��)����TPU 2.0�ȿ�������Ӗ(x��n)����(j��ng)�W(w��ng)�j(lu��)���ֿ���������������(j��)��B��TPU2.0�������Ă�(g��)оƬ��ÿ���̎��180�f(w��n)�|�θ��c(di��n)�\(y��n)�㡣Google߀�ҵ�һ�N������ʹ���µ�Ӌ(j��)��C(j��)�W(w��ng)�j(lu��)��64��(g��)TPU�M�ϵ�һ������(j��)�����^��TPU Pods�����ṩ��s11500�f(w��n)�|�θ��c(di��n)�\(y��n)��������Google��ʾ����˾�µ���ȌW(xu��)��(x��)���gģ�������32�K������õ�GPU��Ӗ(x��n)������Ҫһ����ĕr(sh��)�g�����˷�֮һ��(g��)TPU Pod������6��(g��)С�r(sh��)��(n��i)���ͬ�ӵ��΄�(w��)��ĿǰGoogle ����ֱ�ӳ���TPUоƬ�����ǽY(ji��)�����_Դ��ȌW(xu��)��(x��)���TensorFlow��AI�_�l(f��)���ṩTPU�Ƽ��ٵķ���(w��)���Դ˰l(f��)չTPU2�đ�(y��ng)�ú����B(t��i)������TPU2ͬ�r(sh��)�l(f��)����TensorFlow Research Cloud (TFRC) ��
�����ɼ����⣬���y(t��ng)CPU/GPU�S��Intel��AMDҲ��Ŭ���M(j��n)���@Training�Ј�(ch��ng)����Intel�Ƴ���Xeon Phi+Nervana������AMD����һ��VEGA�ܘ�(g��u)GPUоƬ�ȣ�����Ŀǰ�Ј�(ch��ng)�M(j��n)չ�������y��(du��)NVIDIA��(g��u)�����{������(chu��ng)��˾�У�Graphcore ��IPU̎����(IntelligenceProcessing Unit)��(j��)��BҲͬ�r(sh��)֧��Training��Inference��ԓIPU����ͬ��(g��u)��˼ܘ�(g��u)���г��^1000��(g��)��(d��)����̎������֧��All-to-All�ĺ��gͨ�ţ�����BulkSynchronous Parallel��ͬ��Ӌ(j��)��ģ�ͣ����ô���Ƭ��Memory����ֱ���B��DRAM��
��֮����(du��)���ƶ˵�Training(Ҳ����Inference)ϵ�y(t��ng)���f���I(y��)����^һ�µ��^�c(di��n)�Ǹ�(j��ng)��(zh��ng)�ĺ��IJ����چ�һоƬ�Č��棬��������(g��)ܛӲ�����B(t��i)�Ĵ��NVIDIA��CUDA+GPU��Google��TensorFlow+TPU2.0�����^�ĸ�(j��ng)��(zh��ng)Ҳ�ń����_ʼ��
������Inference On Cloud�ƶ�����
����(du��)��Training�Ј�(ch��ng)��NVIDIA��һ�Ҫ�(d��)��Inference�Ј�(ch��ng)��(j��ng)��(zh��ng)�t�����ɢ������I(y��)�����f����ȌW(xu��)��(x��)�Ј�(ch��ng)ռ��(Trainingռ5%��Inferenceռ95%)��Inference�Ј�(ch��ng)��(j��ng)��(zh��ng)��Ȼ��(hu��)���鼤�ҡ�
���ƶ������h(hu��n)��(ji��)���mȻGPU���Б�(y��ng)�ã����������(y��u)�x������Dz��î���(g��u)Ӌ(j��)�㷽��(CPU/GPU +FPGA/ASIC)������ƶ������΄�(w��)��FPGA�I(l��ng)���Ĵ�S��(Xilinx/Altera/Lattice/Microsemi)�е�Xilinx��Altera����Intel��ُ(g��u)�����ƶ˼����I(l��ng)��(y��u)��(sh��)���@��Altera��2015��12�±�Intel��ُ(g��u)���S���Ƴ���Xeon+FPGA���ƶ˷�����ͬ�r(sh��)�cAzure���vӍ�ơ������ƵȾ��к�����Xilinx�t�cIBM���ٶ��ơ�AWS���vӍ�ƺ����^���룬����Xilinx߀��(zh��n)��Ͷ�Y�ˇ�(gu��)��(n��i)AIоƬ����(chu��ng)��˾���b�Ƽ���Ŀǰ�������ƶ˼����I(l��ng)������FPGA�S���cXilinx��Altera߀�кܴ��ࡣ

ASIC�I(l��ng)��(y��ng)�����ƶ�����������AIоƬĿǰ��Ҫ��Google��TPU1.0/2.0�����У�TPU1.0�H����Datacenter Inference��(y��ng)�á����ĺ�������65,536��(g��)8-bit MAC�M�ɵľ�ꇳ˷���Ԫ����ֵ�����_(d��)��92 TeraOps/second(TOPS)����һ��(g��)�ܴ��Ƭ�ϴ惦(ch��)����һ��28 MiB��������֧��MLP��CNN��LSTM�@Щ��Ҋ����(j��ng)�W(w��ng)�j(lu��)������֧��TensorFLow��ܡ�����ƽ������(TOPS)�����_(d��)��CPU��GPU��15��30�����ܺ�Ч��(TOPS/W)�ܵ�30��80�������ʹ��GPU��DDR5 memory���@�ɂ�(g��)��(sh��)ֵ�����_(d��)����sGPU��70����CPU��200����TPU 2.0������Ӗ(x��n)����Ҳ������������һ��(ji��)�ѽ�(j��ng)���^��B��
��(gu��)��(n��i)AIоƬ��˾����o(j��)�Ƽ���(j��)��(b��o)��Ҳ�������аl(f��)�ƶ˸�����AIоƬ��Ŀǰ�c�ƴ�Ӎ�w�����Ⱦ��к�������Ŀǰ߀�]��Ԕ��(x��)�Įa(ch��n)Ʒ��B��
������Inference On Device�O(sh��)�������
�O(sh��)��������đ�(y��ng)�È�(ch��ng)��������ӻ��������֙C(j��)��ADAS�����ܔz���^���Z(y��)��������VR/AR���O(sh��)�������������Ҫ���鶨�ƻ������ġ��ͳɱ���Ƕ��ʽ��Q�������@�ͽo�˄�(chu��ng)�I(y��)��˾�����C(j��)��(hu��)���Ј�(ch��ng)��(j��ng)��(zh��ng)���B(t��i)Ҳ��(hu��)���Ӷ��ӻ���

1�������֙C(j��)
�A��9�³��l(f��)��������970 AIоƬ�ʹ��d����(j��ng)�W(w��ng)�j(lu��)̎����NPU(����o(j��)IP)������970������TSMC 10nm��ˇ�Ƴ̣�����55�|��(g��)���w�ܣ����������һ��оƬ����20%��CPU�ܘ�(g��u)�����4��A73+4��A53�M��8���ģ��ܺ�ͬ����һ��оƬ�õ�20%��������GPU���������12��Mali G72 MP12GPU���ڈD��̎���Լ���Ч���(xi��ng)�P(gu��n)�Iָ��(bi��o)����քe����20%��50%��NPU����HiAI�Ƅ�(d��ng)Ӌ(j��)��ܘ�(g��u)����FP16���ṩ���\(y��n)�����ܿ����_(d��)��1.92 TFLOPs������Ă�(g��)Cortex-A73���ģ�̎��ͬ�ӵ�AI�΄�(w��)���д�s50����Ч��25�����܃�(y��u)��(sh��)��
�O�����°l(f��)����A11����оƬҲ���d����(j��ng)�W(w��ng)�j(lu��)��Ԫ����(j��)��B��A11����оƬ��43�|��(g��)���w�ܣ�����TSMC 10�{��FinFET��ˇ�Ƴ̡�CPU�������������O(sh��)Ӌ(j��)����2��(g��)�����ܺ����c4��(g��)����Ч���ĽM�ɡ����A10 Fusion�����Ѓɂ�(g��)���ܺ��ĵ��ٶ�������25%���Ă�(g��)��Ч���ĵ��ٶ�������70%��GPU�������O�������O(sh��)Ӌ(j��)�������� GPU �D��̎���Ԫ���D��̎���ٶ��c��һ���������������_(d��) 30% ֮�ࣻ��(j��ng)�W(w��ng)�j(lu��)����NPU�����p���O(sh��)Ӌ(j��)��ÿ���\(y��n)��Δ�(sh��)��߿��_(d��) 6000 �|�Σ���Ҫ���ڄ��ΙC(j��)���W(xu��)��(x��)�΄�(w��)���܉��R(sh��)�e������c(di��n)�����w�ȣ��܉�֓�(d��n) CPU �� GPU ���΄�(w��)���������оƬ���\(y��n)��Ч�ʡ�
���⣬��ͨ�� 2014 ���_ʼҲ���_��NPU���аl(f��)�����������ɴ���� 8xx оƬ�϶������w�F(xi��n)��������� 835 �ͼ����ˡ������(j��ng)̎������ܛ����ܡ����ṩ��(du��)������(j��ng)�W(w��ng)�j(lu��)�ӵ�֧�֣�OEM �S�̺�ܛ���_�l(f��)�̶����Ի��ڴ˴����Լ�����(j��ng)�W(w��ng)�j(lu��)��Ԫ��ARM�ڽ������l(f��)���� Cortex-A75 �� Cortex-A55��Ҳ�������Լҵ�AI ��(j��ng)�W(w��ng)�j(lu��)DynamIQ���g(sh��)����(j��)��B��DynamIQ���g(sh��)��δ�� 3-5 ���(n��i)�Ɍ�(sh��)�F(xi��n)�Ȯ�(d��ng)ǰ�O(sh��)���50����AI���ܣ��Ɍ��ض�Ӳ���������ķ���(y��ng)�ٶ�����10�������w�����������֙C(j��)δ��AIоƬ�����B(t��i)�������Ԕඨ�ԕ�(hu��)�����ڂ��y(t��ng)SoC�����С�

2���Ԅ�(d��ng)�{�
NVIDIAȥ��l(f��)���Ԅ�(d��ng)�{��_�l(f��)ƽ�_(t��i)DRIVE PX2������16nm FinFET��ˇ�����ĸ��_(d��)250W������ˮ��ɢ���O(sh��)Ӌ(j��)��֧��12·�z���^ݔ�롢���ⶨλ�����_(d��)�ͳ�����������CPU���Ã��w��һ��NVIDIA Tegra̎��������(d��ng)�а�����8��(g��)A57���ĺ�4��(g��)Denver���ģ�GPU������һ��Pascal�ܘ�(g��u)���ξ���Ӌ(j��)�������_(d��)��8TFlops����ԽTITAN X���к���10�����ϵ���ȌW(xu��)��(x��)Ӌ(j��)��������Intel��ُ(g��u)��Mobileye����ͨ��ُ(g��u)��NXP��Ӣ�w�衢���_����܇��Ӿ��^Ҳ�ṩADASоƬ���㷨������(chu��ng)��˾�У���ƽ������ȌW(xu��)��(x��)̎����(BPU��BrainProcessor Unit)IP�����������(Hugo)ƽ�_(t��i)Ҳ�����c(di��n)�����Ԅ�(d��ng)�{��I(l��ng)��
3��Ӌ(j��)��C(j��)ҕ�X�I(l��ng)��
Intel��ُ(g��u)��Movidius����Ҫ��оƬ�ṩ�̣��o(w��)�˙C(j��)��������ҕ�ʹ��A�ɷݵ����ܱO(ji��n)��?c��i)z���^��ʹ����Movidius��Myriadϵ��оƬ��Ŀǰ��(gu��)��(n��i)��Ӌ(j��)��C(j��)ҕ�X���g(sh��)�Ĺ�˾�У��̜��Ƽ���Face++���Əġ����D�ȣ�δ���п����S��������Ӌ(j��)��C(j��)ҕ�X���g(sh��)�ķe�u����ֹ�˾����������ȥ��CVоƬ�аl(f��)�����⣬��(gu��)��(n��i)߀�����������ܡ���оԭ��(d��ng)�Ȅ�(chu��ng)�I(y��)��˾�ṩ�z���^�˵�AI����IP��оƬ��Q������
4������
VR�O(sh��)��оƬ�Ĵ����ܛ������VR�O(sh��)��Hololens���аl(f��)��HPUоƬ���@�w���_(t��i)�e늴�����оƬ��ͬ�r(sh��)̎�����5��(g��)�z���^��һ��(g��)��Ȃ������Լ��\(y��n)��(d��ng)�������Ĕ�(sh��)��(j��)�����߂�Ӌ(j��)��C(j��)ҕ�X�ľ���\(y��n)���CNN�\(y��n)��ļ��ٹ��ܣ��Z(y��)�������O(sh��)��оƬ���棬��(gu��)��(n��i)�І�Ӣ̩���Լ���֪�ɼҹ�˾�����ṩ��оƬ��������(n��i)���˞��Z(y��)���R(sh��)�e����(y��u)���������(j��ng)�W(w��ng)�j(lu��)���ٷ�������(sh��)�F(xi��n)�O(sh��)����Z(y��)���x���R(sh��)�e���ڷ�IOT�I(l��ng)��NovuMind�O(sh��)Ӌ(j��)��һ�N�Hʹ��3��3���e�^�V����AIоƬ����һ��оƬԭ���A(y��)Ӌ(j��)������Ƴ����A(y��)Ӌ(j��)�Ɍ�(sh��)�F(xi��n)���ܲ����^5���M(j��n)��15�f(w��n)�|�θ��c(di��n)�\(y��n)�㣬���ԏV����(y��ng)���ڸ��С�͵Ļ�(li��n)�W(w��ng)��߅�����O(sh��)�䡣
���ģ��¼ܘ�(g��u) - ��XӋ(j��)��оƬ
����XоƬ����ָ�������X��(j��ng)Ԫ�Y(ji��)��(g��u)�����X��֪�J(r��n)֪��ʽ���O(sh��)Ӌ(j��)��оƬ����Ŀ��(bi��o)���_�l(f��)�������T���Z�����ܘ�(g��u)�wϵ��оƬ���@һ�I(l��ng)��Ŀǰ��̎��̽���A�Σ���W��֧�ֵ�SpiNNaker��BrainScaleS��˹̹����W(xu��)��Neurogrid��IBM��˾��TrueNorth�Լ���ͨ��˾��Zeroth�ȣ���(gu��)��(n��i)Westwell�����A��W(xu��)���㽭��W(xu��)����ӿƼ���W(xu��)��Ҳ�����P(gu��n)�о���

IBM��TrueNorth��2014�깫������һ�wоƬ�ϼ�����4096��(g��)��(n��i)�ˣ�100�f(w��n)��(g��)��(j��ng)Ԫ��2.56�|��(g��)�ɾ���ͻ�|��ʹ�������ǵ�28nm�Ĺ�ˇ����540�f(w��n)��(g��)���w�ܣ�ÿ��Ɉ�(zh��)��460�|��ͻ�|�\(y��n)�㣬�����Ğ�70mW��ÿƽ��������20mW��IBM����KĿ��(bi��o)����ϣ������һ�_(t��i)����100�|��(g��)��(j��ng)Ԫ��100�f(w��n)�|��(g��)ͻ�|��Ӌ(j��)��C(j��)���@�ӵ�Ӌ(j��)��C(j��)Ҫ������X�Ĺ�����(qi��ng)��10 ����������ֻ��һǧ�ߣ�������������������

��(gu��)��(n��i)AI����(chu��ng)��˾�����Ƽ�Westwell����FPGAģ�M��(j��ng)Ԫ�Ԍ�(sh��)�F(xi��n)SNN�Ĺ�����ʽ���Ѓɿ�a(ch��n)Ʒ��
-
������X��(j��ng)ԪоƬDeepSouth(����)���������}�_��(j��ng)�W(w��ng)�j(lu��)оƬSNN������STDP(spike-time-dependentplasticity)���㷨��(g��u)��������ͻ�|��(j��ng)�W(w��ng)�j(lu��)�����·ģ�M�挍(sh��)������(j��ng)Ԫ�a(ch��n)���}�_�ķ����W(xu��)оƬ��ͨ�^��(d��ng)�B(t��i)����ķ�����ģ�M�����_(d��)5000�f(w��n)��(j��)�e�ġ���(j��ng)Ԫ�������Ğ���y(t��ng)оƬ��ͬһ�΄�(w��)�µĎ�ʮ��֮һ���װٷ�֮һ��
-
��ȌW(xu��)��(x��)��X��(j��ng)ԪоƬDeepWell(�)��̎��ģʽ�R(sh��)�e���}��ͨ������оƬ�������ھ�����������㷨(OPIUM lite)��(du��)оƬ����(j��ng)Ԫ�g���B�ә�(qu��n)���M(j��n)�ЌW(xu��)��(x��)���{(di��o)������12800�f(w��n)��(g��)��(j��ng)Ԫ��ͨ�^����ָ��{(di��o)��оƬ����(j��ng)Ԫ�YԴ�ķ��䣻�W(xu��)��(x��)�c�R(sh��)�e�ٶ��h(yu��n)�h(yu��n)�����\(y��n)����ͨ��Ӳ��(��CPU, GPU)�ϵĂ��y(t��ng)����(��CNN)���ҹ��ĸ��͡�
���w��������XӋ(j��)��оƬ�I(l��ng)����̎��̽���A�Σ����xҎ(gu��)ģ���������б��^�h(yu��n)�ľ��x��
�Ї�(gu��)AIо��˾
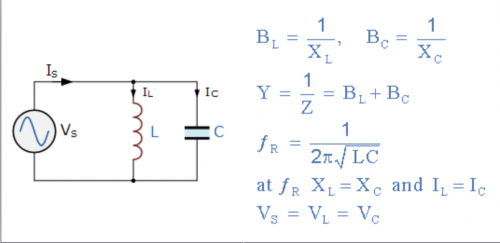
�vӍAI�a(ch��n)�I(y��)��(b��o)�����ᵽ�Ї�(gu��)��AI��̎����/оƬ��I(y��)һ����14�ң��҂����չ��_�Y�������˲��և�(gu��)��(n��i)AI̎����/оƬ��˾���m����䣬���o���dȤ���x������(g��)������
1������o(j��)�Ƽ�&Cambricon 1A
����o(j��)�Ƽ�������2016�꣬�����ڱ�������(chu��ng)ʼ�����п�ԺӋ(j��)���������ʯ������V�ֵܣ����ڄ��������һ�|��ԪA݆���Y������Ͱ̈́�(chu��ng)Ͷ��(li��n)�넓(chu��ng)Ͷ����(gu��)��Ͷ�Y���пƈD�`��Ԫ��ԭ�c(di��n)��ӿ�fͶ�Y(li��n)��Ͷ�Y���ɞ�ȫ��AIоƬ�I(l��ng)���һ��(g��)��(d��)�ǫF����(chu��ng)��˾��
����o(j��)��ȫ���һ��(g��)�ɹ���Ƭ�����г���a(ch��n)Ʒ��AIоƬ��˾�����нK��AI̎����IP���ƶ˸�����AIоƬ�ɗl�a(ch��n)Ʒ����2016��l(f��)���ĺ���o(j��)1A̎����(Cambricon-1A)��������������ȌW(xu��)��(x��)����̎���������������֙C(j��)�������O(ji��n)�ء��o(w��)�˙C(j��)���ɴ����O(sh��)���Լ������{�ȸ�K���O(sh��)�䣬���\(y��n)�����������㷨�r(sh��)���ܹ��ı�ȫ�泬Խ���y(t��ng)̎������
2����ƽ���C(j��)����&BPU/�P��
��ƽ���C(j��)���˳�����2015�꣬�����ڱ�������(chu��ng)ʼ����ǰ�ٶ���ȌW(xu��)��(x��)�о�Ժؓ(f��)؟(z��)�����P����˾��ȥ���������A+݆���Y��Ͷ�Y�������˳��d�Y��������Y�����tɼ�Y������ɳ����(chu��ng)Ͷ�������Y������(chu��ng)�¹���(ch��ng)���������p��Ͷ�Y�����Ƅ�(chu��ng)Ͷ�����Ͷ�Y��DST�ȡ���(j��)��B����˾���ڼ������B݆���Y��
BPU(BrainProcessing Unit)�ǵ�ƽ���C(j��)���������O(sh��)Ӌ(j��)�аl(f��)��Ч���˹�����̎�����ܘ�(g��u)IP��֧��ARM/GPU/FPGA/ASIC��(sh��)�F(xi��n)����ע���Ԅ�(d��ng)�{��Ę�D����R(sh��)�Ȍ����I(l��ng)��2017�꣬��ƽ�����ڸ�˹�ܘ�(g��u)��Ƕ��ʽ�˹����ܽ�Q��������(hu��)�������{�������������������(g��)�I(l��ng)���M(j��n)�Б�(y��ng)�ã���һ��BPUоƬ���P�š�Ŀǰ���M(j��n)����Ƭ�A�Σ��A(y��)Ӌ(j��)�ڽ����°����Ƴ�����֧��1080P�ĸ���D��ݔ�룬ÿ���̎��30�����z�y(c��)��ۙ��(sh��)�ق�(g��)Ŀ��(bi��o)����ƽ���ĵ�һ��BPU����TSMC��40nm��ˇ������(du��)�ڂ��y(t��ng)CPU/GPU,��Ч��������2~3��(g��)��(sh��)����(j��)(100~1,000������)��
3�����b�Ƽ�&DPU
���b�Ƽ�������2016�꣬�����ڱ����������A��W(xu��)�c˹̹����W(xu��)������피���ȌW(xu��)��(x��)Ӳ���о��߄�(chu��ng)��������������A݆���Y��Ͷ�Y��������(li��n)�l(f��)�ơ�ِ�`˼����ɳ����(chu��ng)Ͷ�������Y�������A�عɡ������Y���ȡ�
���b�Ƽ������_�l(f��)�Ļ���FPGA����(j��ng)�W(w��ng)�j(lu��)̎�����Q��DPU����Ŀǰ��ֹ�����b���_�l(f��)���˃ɿ�DPU������ʿ��¼ܘ�(g��u)�͵ѿ����ܘ�(g��u)�����У�����ʿ��¼ܘ�(g��u)��ᘌ�(du��)���e��(j��ng)�W(w��ng)�j(lu��)CNN���O(sh��)Ӌ(j��)���ѿ����ܘ�(g��u)����̎��DNN/RNN�W(w��ng)�j(lu��)���O(sh��)Ӌ(j��)���Ɍ�(du��)��(j��ng)�^�Y(ji��)��(g��u)���s���ϡ����(j��ng)�W(w��ng)�j(lu��)�M(j��n)�ИO�¸�Ч��Ӳ�����١�����(du��)�� Intel XeonCPU �c Nvidia TitanX GPU����(y��ng)�õѿ����ܘ�(g��u)��̎������Ӌ(j��)���ٶ��Ϸքe���189���c13��������24000���c3000��������Ч��
4�������Ƽ�&DeepSouth/DeepWell
��˾������2015�꣬�������Ϻ�������6�������A݆���Y��Ͷ�Y�������ˏ�(f��)��ͬ�ơ�Դ��Ͷ�Y������Ͷ�Y��ʮ�S�Y������A�Y���ȡ�
�����Ƽ�����FPGAģ�M��(j��ng)Ԫ�Ԍ�(sh��)�F(xi��n)SNN�Ĺ�����ʽ���Ѓɿ�a(ch��n)Ʒ��
-
������X��(j��ng)ԪоƬDeepSouth(����)���������}�_��(j��ng)�W(w��ng)�j(lu��)оƬSNN������STDP(spike-time-dependentplasticity)���㷨��(g��u)��������ͻ�|��(j��ng)�W(w��ng)�j(lu��)�����·ģ�M�挍(sh��)������(j��ng)Ԫ�a(ch��n)���}�_�ķ����W(xu��)оƬ��ͨ�^��(d��ng)�B(t��i)����ķ�����ģ�M�����_(d��)5000�f(w��n)��(j��)�e�ġ���(j��ng)Ԫ�������Ğ���y(t��ng)оƬ��ͬһ�΄�(w��)�µĎ�ʮ��֮һ���װٷ�֮һ��
-
��ȌW(xu��)��(x��)��X��(j��ng)ԪоƬDeepWell(�)��̎��ģʽ�R(sh��)�e���}��ͨ������оƬ�������ھ�����������㷨(OPIUM lite)��(du��)оƬ����(j��ng)Ԫ�g���B�ә�(qu��n)���M(j��n)�ЌW(xu��)��(x��)���{(di��o)������12800�f(w��n)��(g��)��(j��ng)Ԫ��ͨ�^����ָ��{(di��o)��оƬ����(j��ng)Ԫ�YԴ�ķ��䣻�W(xu��)��(x��)�c�R(sh��)�e�ٶ��h(yu��n)�h(yu��n)�����\(y��n)����ͨ��Ӳ��(��CPU, GPU)�ϵĂ��y(t��ng)����(��CNN)���ҹ��ĸ��͡�
5�����w��(l��)��&IPU
��˾������2014�꣬���������ڣ��ɇ�(gu��)�ҡ�ǧ��Ӌ(j��)������Ƹ����ꐌ����������ʿ(li��n)�τ�(chu��ng)��������3�������A݆���Y��Ͷ�Y���ɺ��Y������Ͷ�ء��t��ӯ�š�ɽˮ����Ͷ�Y��Ͷ�ؖ|����������ȡ�
�����(l��)�w�ṩҕ�X����оƬ�ͽ�Q��������ע���˹������I(l��ng)��������̎�������C(j��)���W(xu��)��(x��)�c��(sh��)��(j��)���g(sh��)����ġ���˾�����аl(f��)��̎����оƬIPU��������ȫ�µ�����ҕ�XӋ(j��)���̎����оƬ�ܘ�(g��u)��ԓ���g(sh��)���C(j��)���W(xu��)��(x��)Ч�������˃ɂ�(g��)��(sh��)����(j��)����˾�������ڴ�ą^(q��)��(j��)����ϵ�y(t��ng)����(sh��)�F(xi��n)��ȫ���ׄ�(chu��ng)�ġ����f(w��n)��Ⱥ���뼉(j��)��λ����߀���ɼ{��2016�꺼��G20���(hu��)�͞��(zh��n)��(li��n)�W(w��ng)���(hu��)�İ�ȫϵ�y(t��ng)�ṩ����(w��)��
6����������&FaceOS
�������ܳ�����2016�꣬��ARM OpenAI��(sh��)�(y��n)�Һ��ĺ�����I(y��)����˾��ȥ��������ARM��Ӣ�Z��ʹ�������ʹ݆���Y����(j��)��(b��o)��Ŀǰ���چ���(d��ng)��һ݆���Y��
���������ṩһ��(g��)��ARM����Ę�R(sh��)�e����оƬ��ģ�M�������R(sh��)�eģ�M�Ǫ�(d��)��(chu��ng)��֧����ȌW(xu��)��(x��)�㷨��Ƕ��ʽ������ARMƽ�_(t��i)��֧����Ӕz��C(j��)��ҕ�l���z�y(c��)���dȡ��Ę��Ƭ�ȹ��ܡ���(j��)��B���������ܰl(f��)���ġ�����о���LJ�(gu��)��(n��i)�ׂ�(g��)��Ę�R(sh��)�eӲ��ģ�M���ߴ�H��86mm*56mm*21mm���������˹����ܲ���ϵ�y(t��ng)FaceOS��ͨ�^���˹������㷨�M(j��n)�м��ɮa(ch��n)Ʒ�����܉�Ѯa(ch��n)Ʒ���аl(f��)���ڜp��60%���ɱ�����50%��
7����Ӣ̩��&CI1006
��Ӣ̩����2015��11���ڳɶ���������һ���Z(y��)���R(sh��)�eоƬ�аl(f��)�̣�Ͷ�Y��������Roobo���R��Ϣ�ȡ�
��Ӣ̩����CI1006�ǻ���ASIC�ܘ�(g��u)���˹������Z(y��)���R(sh��)�eоƬ���������X��(j��ng)�W(w��ng)�j(lu��)̎��Ӳ����Ԫ���܉�����֧��DNN�\(y��n)��ܘ�(g��u)���M(j��n)�и����ܵĔ�(sh��)��(j��)����Ӌ(j��)�㣬�ɘO�������˹�������ȌW(xu��)��(x��)�Z(y��)�����g(sh��)��(du��)������(sh��)��(j��)��̎��Ч�ʡ�
8����֪&UniOneоƬ
��֪��һ�������Z(y��)���R(sh��)�e���g(sh��)��˾��������2012�꣬����λ�ڱ���������8�����@��3�|����ő�(zh��n)��Ͷ�Y�����в����Y�������ڼӴ��˹����܌���оƬUniOne���аl(f��)���ȡ�
UniOne����(n��i)��DNN̎���Ԫ�����ݶ������L(f��ng)�������ϵ�y(t��ng)����(du��)�κεĈ�(ch��ng)���������ƣ��o(w��)Փ�������ܵĿ��{(di��o)�ϡ�܇�d�ϻ����������O(sh��)���϶�����ֲ���@��(g��)оƬ��ԓоƬ���и��ɶȵģ����ġ��ͳɱ��ă�(y��u)�c(di��n)���c��ͬ�r(sh��)����˾߀��IVM-M������Ƕ��ʽоƬ�����ڸ�ͨwifiģ�M���ṩ���ԃr(ji��)�ȵ���(li��n)�W(w��ng)�Z(y��)���������w��������Ҫ��(y��ng)�������ܿ��{(di��o)���N늵��ܼҾ߮a(ch��n)Ʒ�ϣ�����Linuxϵ�y(t��ng)�O(sh��)Ӌ(j��)��UnitoyоƬ��һվʽ��Q��ͯ���ʽ�C(j��)���˵Ć��ѡ��R(sh��)�e���O(sh��)�以(li��n)������
9���ٶ�&XPU
�ٶ�2017��8��Hot Chips���(hu��)�ϰl(f��)����XPU���@��һ��256�ˡ�����FPGA����Ӌ(j��)�����оƬ�����������ِ˼�`(Xilinx)��XPU������һ�� AI ̎���ܘ�(g��u)������GPU��ͨ���Ժ�FPGA�ĸ�Ч�ʺ͵��ܺģ���(du��)�ٶȵ���ȌW(xu��)��(x��)ƽ�_(t��i)PaddlePaddle���˸߶ȵă�(y��u)���ͼ��١���(j��)��B��XPU�P(gu��n)עӋ(j��)���ܼ��͡�����Ҏ(gu��)�t�Ķ��ӻ�Ӌ(j��)���΄�(w��)��ϣ�����Ч�ʺ����ܣ����������CPU���`���ԡ���ĿǰXPU����Ƿȱ�����ǿɾ������������@Ҳ���漰FPGA�r(sh��)�ձ���ڵĆ��}����Ŀǰ��ֹ��XPU��δ�ṩ���g����
10��NovuMind
NovuMind������2015�꣬��˾��(chu��ng)ʼ����ԭ�ٶȮ���(g��u)Ӌ(j��)��С�Mؓ(f��)؟(z��)�˅��g���ڱ���������O(sh��)���k���ҡ���˾��2017��������A݆���Y��Ͷ�Y�������������𡢌����Y����Ӣ�Z��ʹ���𡢺�̩�������Ƅ�(chu��ng)Ͷ���O�͎̈́�(chu��ng)Ͷ�ȣ���(j��)��(b��o)���������ڻI����һ݆���Y��
NovuMind��Ҫ�����ܞ���܇���������t(y��)�������ڵ��I(l��ng)���ṩASICоƬ�����ṩӖ(x��n)��ģ�͵�ȫ��ʽAI��Q�������cNvidia GPU��Cadence DSP��ͨ����ȌW(xu��)��(x��)оƬ��ͬ��NovuMind��ע���_�l(f��)һ�N���dz����õ��dz���Ч���M(j��n)������������ȌW(xu��)��(x��)������оƬ��NovuMind�O(sh��)Ӌ(j��)��һ�N�Hʹ��3��3���e�^�V����AIоƬ��ͨ�^ʹ�ê�(d��)�صď���̎���ܘ�(g��u)(tensorprocessing architecture)ֱ�ӌ�(du��)���STensor�M(j��n)��̎������оƬ��֧��Tensorflow��Cafe��Torchģ�͡���NovuMind�ĵ�һ��(g��)AIоƬ(ԭ��)�A(y��)Ӌ(j��)��(hu��)��17��ʥ�Q��(ji��)ǰ�Ƴ���������2�·ݑ�(y��ng)�ó����(zh��n)��;w�����܉���ԓоƬ�ό�(sh��)�F(xi��n)���ܲ����^5���M(j��n)��15�f(w��n)�|�θ��c(di��n)�\(y��n)�㡣NovuMind�ĵڶ���(g��)оƬ�����܌������^1�ߣ�Ӌ(j��)����2018������������
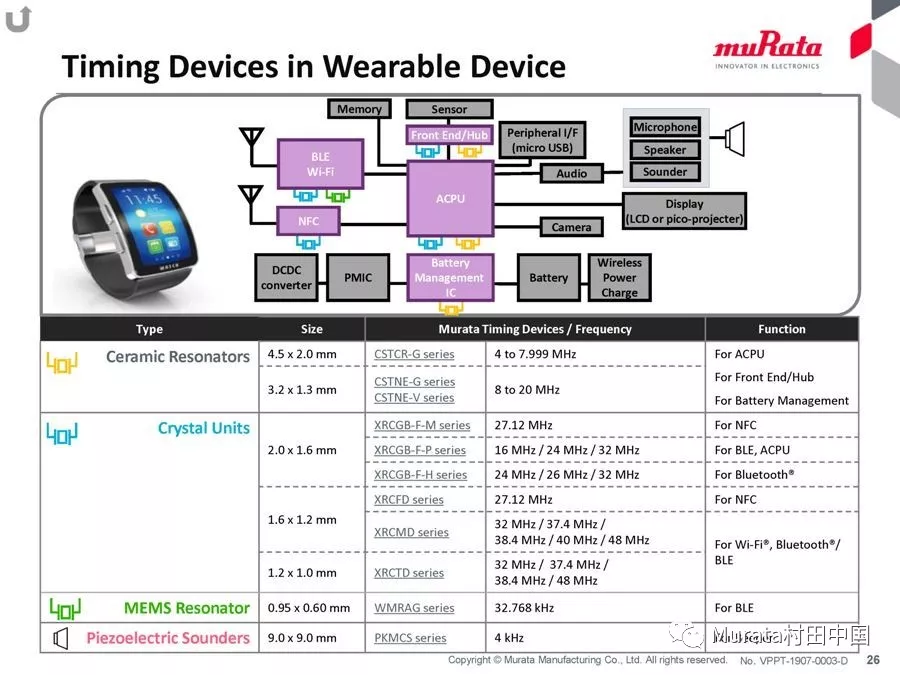
11���A��&����970оƬ
����970���d����(j��ng)�W(w��ng)�j(lu��)̎����NPU�����˺���o(j��)IP������970������TSMC 10nm��ˇ�Ƴ̣�����55�|��(g��)���w�ܣ����������һ��оƬ����20%��CPU�ܘ�(g��u)�����4��A73+4��A53�M��8���ģ��ܺ�ͬ����һ��оƬ�õ�20%��������GPU���������12��Mali G72 MP12GPU���ڈD��̎���Լ���Ч���(xi��ng)�P(gu��n)�Iָ��(bi��o)����քe����20%��50%��NPU����HiAI�Ƅ�(d��ng)Ӌ(j��)��ܘ�(g��u)����FP16���ṩ���\(y��n)�����ܿ����_(d��)��1.92 TFLOPs������Ă�(g��)Cortex-A73���ģ�̎��ͬ�ӵ�AI�΄�(w��)���д�s50����Ч��25�����܃�(y��u)��(sh��)��

12���������&NPU
����2016��6���Ƴ����a(ch��n)��NPUоƬ���ǹ�����һ̖(h��o)����NPU�����ˡ���(sh��)��(j��)�(q��)��(d��ng)����Ӌ(j��)�㡱�ļܘ�(g��u)�����wNPU(28nm)�ܺăH��400mW���O���������Ӌ(j��)�������c���ĵı������e���L(zh��ng)̎��ҕ�l���D��ĺ�����ý�w��(sh��)��(j��)��ÿ��(g��)NPU���Ă�(g��)NPU��(n��i)�˘�(g��u)�ɣ�ÿ��(g��)NPU��(n��i)�˰����ɂ�(g��)��(sh��)��(j��)��̎������һ��(g��)�L(zh��ng)��̎������ÿ��(g��)��(sh��)��(j��)��̎������8��(g��)�L(zh��ng)�ֻ�16��(g��)���ֵ�SIMD(��ָ�����(sh��)��(j��))̎���Ԫ�M�ɣ�ÿ��(g��)NPU��ֵ���ṩ38Gops��76Gops���ֵ�̎��������֧��ͨ�õĻ�����ȌW(xu��)��(x��)����(j��ng)�W(w��ng)�j(lu��)��(ConvolutionLayer/Pooling Layer/Full Connection Layer/Activation Layer/Custom SpecificLayer)��

���σH�����(j��)���_�Y���������և�(gu��)��(n��i)AI̎����/оƬ��˾�����˾�Y�ό������ơ�
��Դ�����Q�Pӛ |

��Ϣ")



